

首先要准备两个游戏的nsp或xci的文件,switch NSCB软件或NSGManager用来解包游戏NCA。解包完成后找到地图所在的文件夹然后用Switch Toolbox解压出来
在此之前我们需要了解一下地图瓦片的墨卡托投影组织方式,它采用金字塔结构,从底层到顶层,分辨率越来越低,但表示的地理范围不变,是一种多分辨率层次模型。该结构以z_x_y来标识瓦片,其中Z表示层级,数字越小,放大比例越大(即显示的地理范围越小、细节越丰富);X为横向瓦片的编号,Y为纵向瓦片的编号。
旷野之息瓦片
1.首先用switch NSCB解包旷野的NCA,首先点击NSCB.exe选择6回车
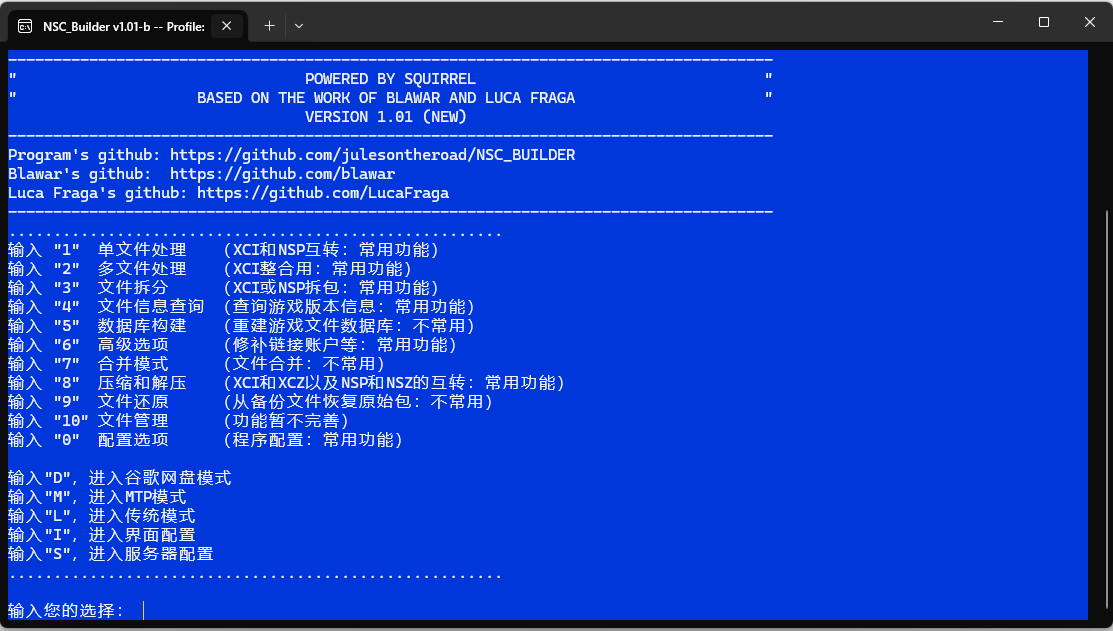
2.然后选择2回车先择你要解包的文件然后选择1回车执行
3.先择4提取NCA
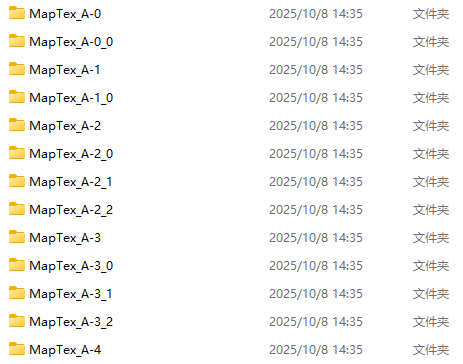
4.解包出来的数据会被放在程序目录下的NSCB_extracted里一般有四个文件夹选其中最大的打开。地图的的文件夹名称叫MapTex直接搜出来就好啦。海拉鲁大陆的地图由12*10共120个正方形的瓦片组成。单个瓦片分辨率为3000*3000像素。
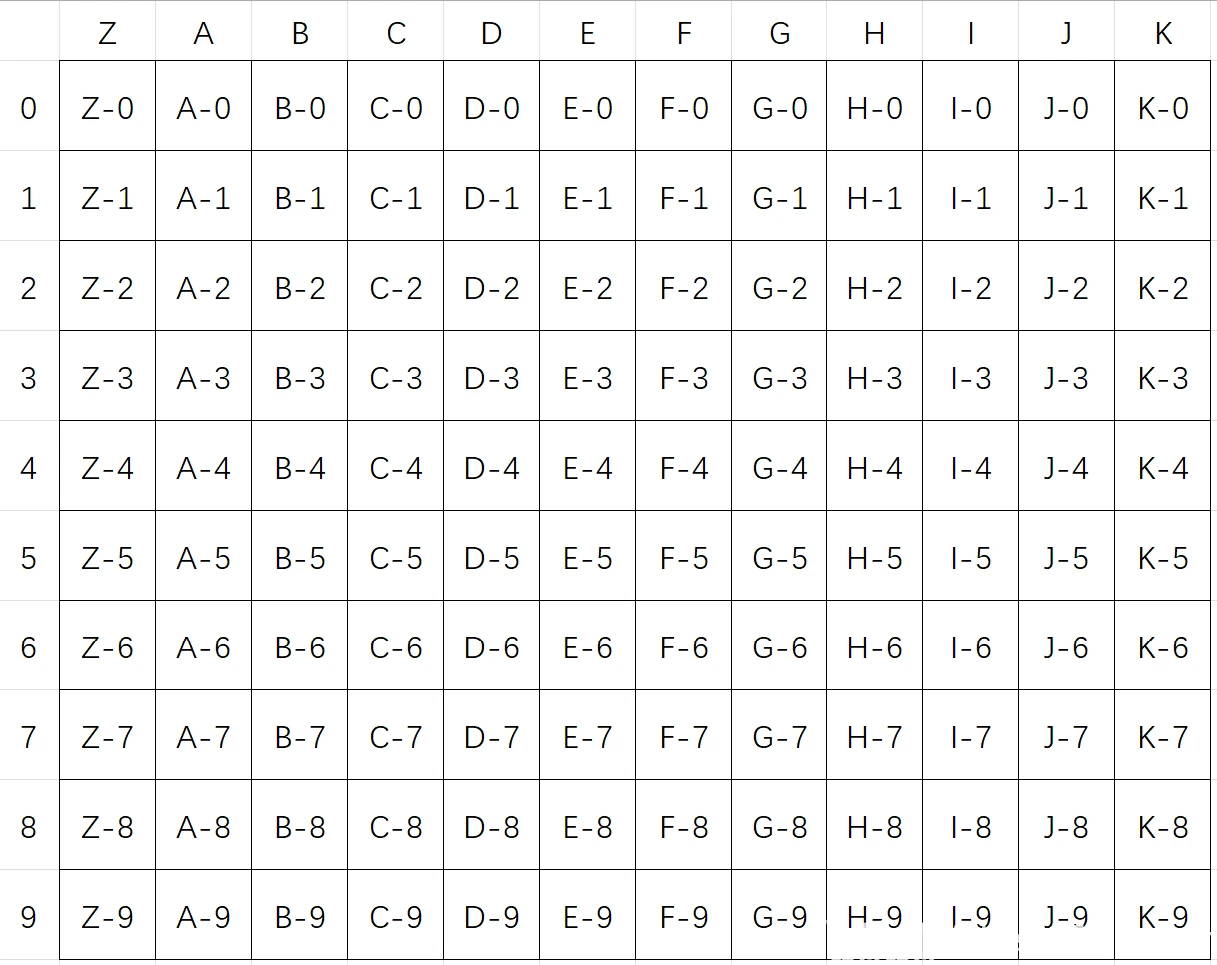
它的命名规则是MapTex_A-1.sbmaptex,其中A代表了X轴,1代表了Y轴,。.sbmaptex是文件格式。如果有 _+字母 的这种则表示同一位置的不同状态不用管,除非你想要哪种有一部分是没解锁状态的效果
5.接下来就是解压后双击打开Toolbox.exe。用Toolbox批量导出图片 单击菜单栏的Tools,单击Batch Export Texture (All Supported Formats),选择需要导出的文件(不是文件夹!)接着选择存储导出后文件的文件夹。然后你就可以得到这样的文件里面就是图片啦
使用python将所需图片单独提取出来并改名
import os
import shutil
import re
# 源文件夹路径(包含要处理的图片文件夹结构,即MapTex所在的上级目录)根据你的实际路径来改
source_folder = r"E:\21002\下载\解包工程"
# 目标统一文件夹路径
target_folder = r"E:\21002\下载\解包工程\unified_images"
# 如果目标文件夹不存在,则创建
if not os.path.exists(target_folder):
os.makedirs(target_folder)
# 遍历源文件夹及其子文件夹
for root, dirs, files in os.walk(source_folder):
for file in files:
if file.endswith(".png"):
file_path = os.path.join(root, file)
# 从文件路径中提取 x、y 相关信息,这里匹配如 MapTex_A-0\MapTex_A-0.png 格式
# 提取 A 作为 x,0 作为 y,z 设为 0(因为结构中无 z 对应值)
match = re.search(r"MapTex_(.)-(\d+)\\MapTex_\1-\2\.png", file_path)
if match:
x = match.group(1)
y = match.group(2)
z = "0"
new_name = f"{x}_{y}_{z}.png"
new_path = os.path.join(target_folder, new_name)
# 复制文件到目标文件夹并改名
shutil.copy2(file_path, new_path)
print(f"已转换:{file_path} -> {new_path}")然后用豆包网页把它拼出来看一下效果怎么样(非常满意)
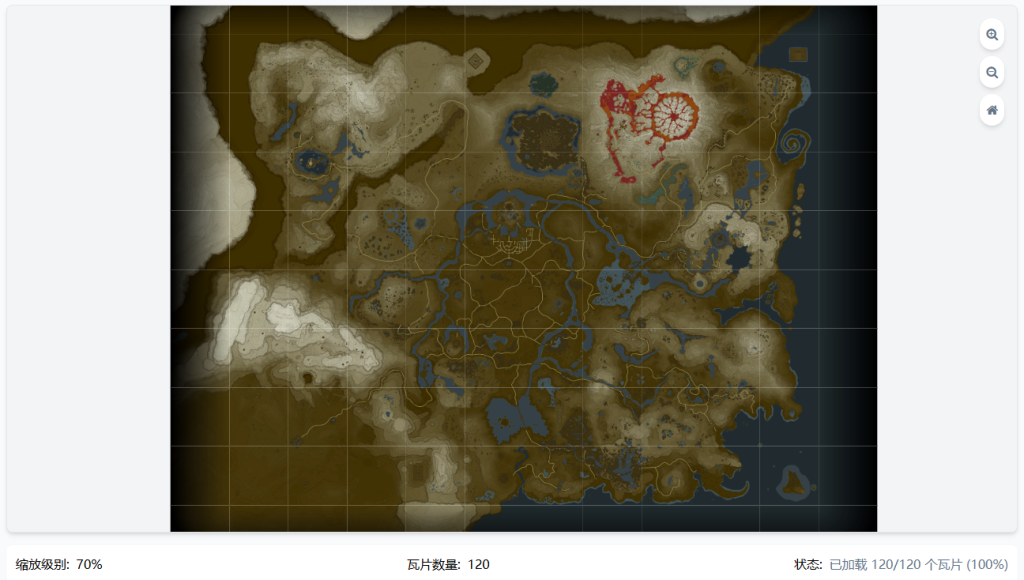
接着我打算转换这些瓦片的命名方式 由于转换格式以后由MapTex_A-0.png变成了A_0_0.png (X_Y→X_Y_Z)我现在要将字母装换成数字以便拼图 (X_Y_Z→Z_X_Y)
import os
import shutil
import re
def rename_tiles(input_dir, output_dir):
# 字母到X的映射(Z→0, A→1, B→2...)
letter_to_x = {
'Z': 0,
'A': 1,
'B': 2,
'C': 3,
'D': 4,
'E': 5,
'F': 6,
'G': 7,
'H': 8,
'I': 9,
'J': 10,
'K': 11
}
# 验证输入目录
if not os.path.isdir(input_dir):
print(f"错误:输入目录不存在 - {input_dir}")
return
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
processed = 0
skipped = 0
# 匹配格式:字母_数字_数字.png(提取字母、Y值)
pattern = re.compile(r'^([A-Z])_(\d+)_(\d+)\.png$')
for filename in os.listdir(input_dir):
file_path = os.path.join(input_dir, filename)
if not os.path.isfile(file_path):
continue
match = pattern.match(filename)
if not match:
print(f"跳过:{filename}(格式不符)")
skipped += 1
continue
letter = match.group(1)
y = match.group(2) # 原始中间数字作为Y值
# 忽略原始最后一个数字(根据你的示例逻辑)
# 严格检查字母映射
if letter not in letter_to_x:
print(f"跳过:{filename}(字母{letter}无映射)")
skipped += 1
continue
x = letter_to_x[letter]
z = 0 # Z固定为0
# 新文件名:Z_X_Y.png
new_filename = f"{z}_{x}_{y}.png"
new_path = os.path.join(output_dir, new_filename)
# 处理可能的重复文件(保留最后一个)
try:
if os.path.exists(new_path):
os.remove(new_path)
shutil.copy2(file_path, new_path)
processed += 1
print(f"成功:{filename} → {new_filename}")
except Exception as e:
print(f"错误:{filename} - {str(e)}")
skipped += 1
print(f"\n处理结果:成功{processed}个,跳过{skipped}个")
print(f"输出目录:{output_dir}")
if __name__ == "__main__":
input_directory = r"E:\21002\下载\解包工程\unified_images"
output_directory = r"E:\21002\下载\解包工程\leaflet_tiles"
rename_tiles(input_directory, output_directory)
输出结果为 重命名成功:A_0_0.png → 0_1_0.png 重命名成功:A_1_0.png → 0_1_1.png 重命名成功:A_2_0.png → 0_1_2.png ....
然后用这个把瓦片拼成一张大图也可以用leaflet用网页浏览还可以添加标点
python拼图
import os
from PIL import Image
from tqdm import tqdm
import logging
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def merge_tiles():
"""合并瓦片图片为一个大图"""
# 在这里设置你的文件地址
input_dir = r"D:/编成备份/Python/leaflet_tiles" # 瓦片目录
output_file = r"D:/编成备份/Python/merged_map000000111.png" # 输出文件
try:
# 收集所有瓦片文件
tile_files = []
for root, _, files in os.walk(input_dir):
for file in files:
if file.lower().endswith(('.png', '.jpg', '.jpeg')):
tile_files.append(os.path.join(root, file))
if not tile_files:
raise FileNotFoundError(f"未找到任何瓦片图片: {input_dir}")
logger.info(f"找到 {len(tile_files)} 个瓦片文件")
# 解析瓦片坐标
tiles = []
for file in tqdm(tile_files, desc="解析瓦片坐标"):
try:
basename = os.path.basename(file)
parts = os.path.splitext(basename)[0].split('_')
if len(parts) == 3: # z_x_y
z, x, y = map(int, parts)
tiles.append({'z': z, 'x': x, 'y': y, 'file': file})
else:
logger.warning(f"无法解析瓦片坐标: {file}")
continue
except (ValueError, IndexError) as e:
logger.warning(f"解析瓦片 {file} 失败: {e}")
if not tiles:
raise ValueError("无法从文件名中解析任何瓦片坐标")
# 计算瓦片网格范围
min_x = min(t['x'] for t in tiles)
max_x = max(t['x'] for t in tiles)
min_y = min(t['y'] for t in tiles)
max_y = max(t['y'] for t in tiles)
logger.info(f"瓦片范围: x={min_x}-{max_x}, y={min_y}-{max_y}")
# 获取单个瓦片尺寸
sample_tile = Image.open(tiles[0]['file'])
tile_width, tile_height = sample_tile.size
sample_tile.close()
logger.info(f"单个瓦片尺寸: {tile_width}×{tile_height}")
# 计算大图尺寸
cols = max_x - min_x + 1
rows = max_y - min_y + 1
total_width = cols * tile_width
total_height = rows * tile_height
logger.info(f"大图尺寸: {total_width}×{total_height} ({cols}列×{rows}行)")
# 创建空白大图
logger.info("开始创建并填充大图...")
merged_image = Image.new('RGB', (total_width, total_height))
# 拼接瓦片
for tile in tqdm(tiles, desc="拼接瓦片"):
try:
img = Image.open(tile['file'])
# 计算瓦片在大图中的位置
x_pos = (tile['x'] - min_x) * tile_width
y_pos = (tile['y'] - min_y) * tile_height
merged_image.paste(img, (x_pos, y_pos))
img.close()
except Exception as e:
logger.error(f"无法处理瓦片 {tile['file']}: {e}")
# 保存大图
output_dir = os.path.dirname(output_file)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir)
merged_image.save(output_file)
logger.info(f"大图已保存到: {output_file}")
return True
except Exception as e:
logger.error(f"拼接过程中发生错误: {e}")
return False
if __name__ == "__main__":
print("开始处理瓦片...")
success = merge_tiles()
if success:
print(f"✅ 拼接完成!")
else:
print("❌ 拼接失败,请检查日志信息") 
王国之泪瓦片
首先第一步和也和上面的旷野一样先用switch NSCB解包NCA,不过我这里不知道什么原因解包不出来所以用NSGManager来解包了
打开NSGManager 选择文件/添加文件/点击游戏封面/右下角选择其中最大的NCA文件/选择提取并解包NCA
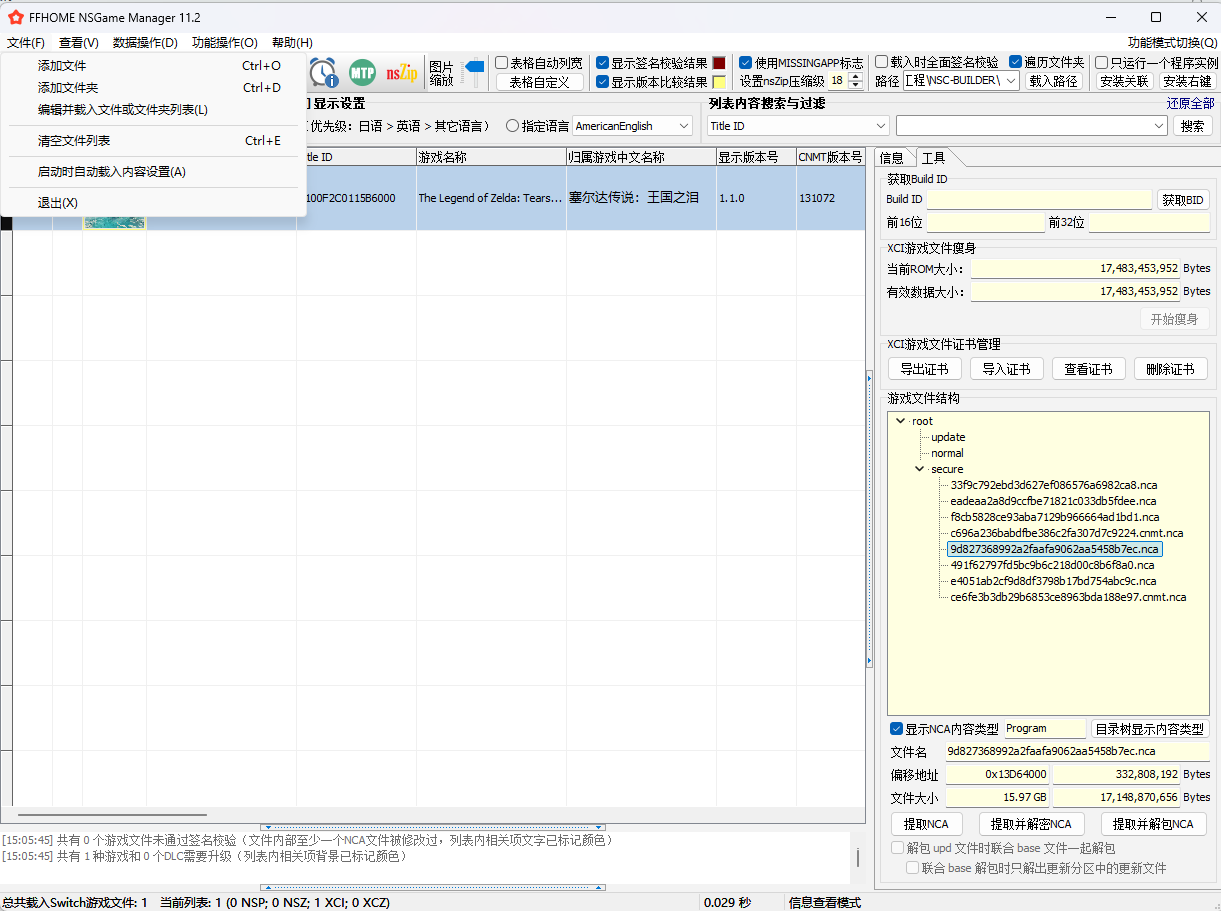
王泪的地图数据和旷野的有点小区别但大致一样。它的文件路径在UI\Map\MainField。当你打开之后会发现一共有三大类文件分别是G开头,S开头,U开头的文件它们分别代表大陆,天空,地底地图。你可以事先先将他们分类然后再用Switch Toolbox解压出来。
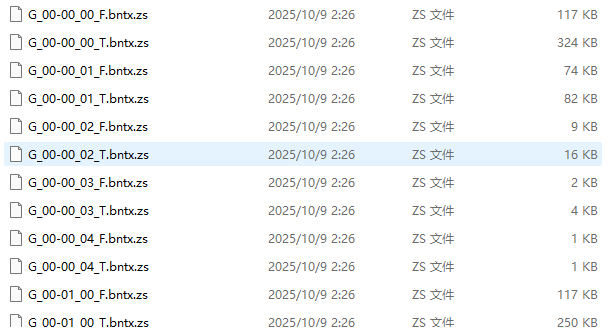
它们的瓦片结构为X_Y_Z其他不用管我们只需要把带T的文件单独拎出来,只要后面带_F的就不要那些事地图没有完全解锁状态下的地图。只保留全是T和T后面带_A或者_B的文件。还有Z为_00的。
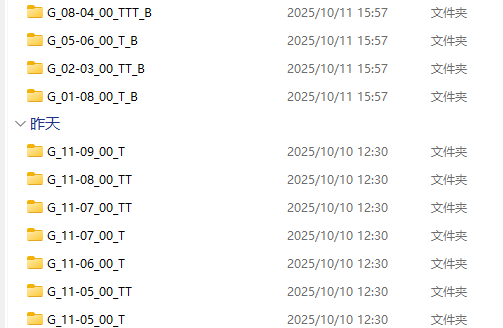
接着就是把这些图片单独提取出来在重命名
import os
import shutil
import re
# 源文件夹路径(包含X_Y_Z格式图片的文件夹)
source_dir = r"E:\21002\下载\解包工程\images"
# 目标文件夹路径(用于存放重命名后的图片)
target_dir = r"E:\21002\下载\解包工程\images_renamed"
# 确保目标文件夹存在
if not os.path.exists(target_dir):
os.makedirs(target_dir)
# 匹配X_Y_Z.png格式的正则表达式
pattern = re.compile(r'^(\d+)_(\d+)_(\d+)\.png$')
# 遍历源文件夹中的所有文件
for file in os.listdir(source_dir):
# 检查是否为文件且匹配X_Y_Z.png格式
file_path = os.path.join(source_dir, file)
if os.path.isfile(file_path) and file.lower().endswith('.png'):
match = pattern.match(file)
if match:
# 提取X、Y、Z的值
x = match.group(1)
y = match.group(2)
z = match.group(3)
# 构建新文件名 Z_X_Y.png
new_filename = f"{z}_{x}_{y}.png"
new_file_path = os.path.join(target_dir, new_filename)
# 复制并重命名文件
shutil.copy2(file_path, new_file_path)
print(f"已重命名: {file} -> {new_filename}")
else:
print(f"跳过非目标格式文件: {file}")
print("重命名完成!")
这里后面带_1或者_2的是同一片区域前期和后期的区别按自己的需求保留删除在手动命名
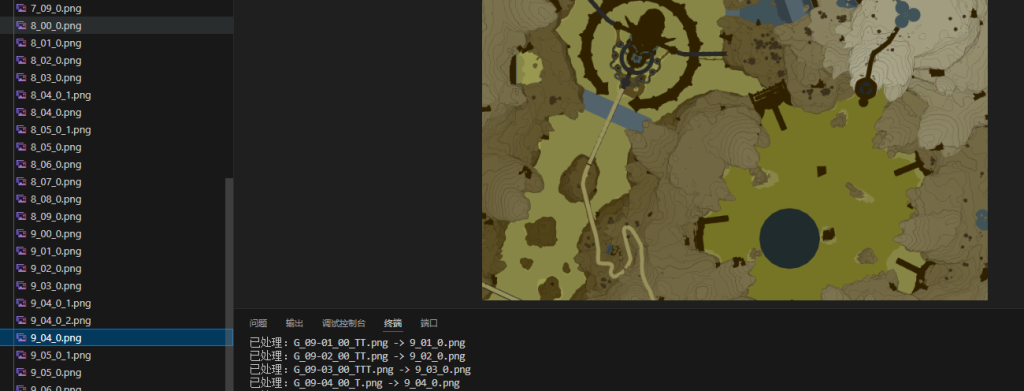
后面的步骤就和前面的一样了,要是你想提取另外的两张地图只需要将代码中pattern = re.compile(r'G_0(\d)-(\d{2})_00_.*?\.png', re.IGNORECASE)的G_改成S_或者U_就可以啦

对了在拼图之前还需要转换一下瓦片的顺序
import os
import shutil
import re
# 源文件夹路径(包含X_Y_Z格式图片的文件夹)
source_dir = r"E:\21002\下载\解包工程\images"
# 目标文件夹路径(用于存放重命名后的图片)
target_dir = r"E:\21002\下载\解包工程\images11"
# 确保目标文件夹存在
if not os.path.exists(target_dir):
os.makedirs(target_dir)
# 匹配X_Y_Z.png格式的正则表达式
pattern = re.compile(r'^(\d+)_(\d+)_(\d+)\.png$')
# 遍历源文件夹中的所有文件
for file in os.listdir(source_dir):
# 检查是否为文件且匹配X_Y_Z.png格式
file_path = os.path.join(source_dir, file)
if os.path.isfile(file_path) and file.lower().endswith('.png'):
match = pattern.match(file)
if match:
# 提取X、Y、Z的值
x = match.group(1)
y = match.group(2)
z = match.group(3)
# 构建新文件名 Z_X_Y.png
new_filename = f"{z}_{x}_{y}.png"
new_file_path = os.path.join(target_dir, new_filename)
# 复制并重命名文件
shutil.copy2(file_path, new_file_path)
print(f"已重命名: {file} -> {new_filename}")
else:
print(f"跳过非目标格式文件: {file}")
print("重命名完成!")
Comments NOTHING